
Jednym z celów każdego wydawcy, który generuje przychody z monetyzacji swojej witryny za pomocą reklam, jest zajęcie jak najwyższej pozycji w wyszukiwarkach. Jednak zanim to nastąpi, strona musi zostać poddana procesom zwanym „crawling” oraz „indexing”. Dzięki nim możliwe jest określenie pozycji każdej strony w rankingu wyszukiwarki. W tym artykule dowiesz się więcej na ich temat, a także o tym, jak możesz zoptymalizować swoją witrynę pod kątem tych procesów. Wyjaśnimy również niektóre z najważniejszych terminów związanych z nimi, jak tzw. pająki (ang. spiders – roboty indeksujące).

Jak działa wyszukiwarka Google
Choć w języku polskim zarówno „crawling”, jak i „indexing” tłumaczy się jako „indeksowanie”, pojęcia te oznaczają zupełnie inne rzeczy. Zanim jednak przejdziemy do wyjaśnienia różnic między nimi, warto poznać definicje kroków prowadzących do wyświetlania i pozycjonowania stron w największej wyszukiwarce – Google:
- „Crawling” to pierwszy krok w procesie, który koncentruje się na znajdywaniu, skanowaniu i pobieraniu treści ze stron internetowych, w tym grafik, filmów wideo, plików PDF i artykułów. Pracę tę wykonują roboty indeksujące, zwane po angielsku pająkami (org. web crawlers lub spiders);
- Głównym celem etapu zwanego „indexing” jest analiza treści i znaczenia tego, co zostało znalezione w poprzednim kroku. Następnie dane te są przechowywane w bazie danych Google – Google index;
- Wyświetlanie wyników wyszukiwania to ostatni etap procesu. Głównym celem Google jest pokazanie użytkownikowi wyników najbardziej odpowiadających jego zapytaniu.
„Indexing” a „crawling”
W celu rozróżnienia tych dwóch pojęć „crawling” możemy przetłumaczyć jako „pełzanie”, od ang. „to crawl” – pełzać. Jak już wspomnieliśmy, koncentruje się ono na wyszukiwaniu, skanowaniu i pobieraniu treści internetowych. Co ciekawe, procesowi temu podlegają tylko witryny dostępne publicznie, więc roboty indeksujące nie mają dostępu do treści „ukrytych” pod stroną logowania (innymi słowy, dostępnych dopiero po zalogowaniu). W przypadku wyszukiwarki Google, robot wykonujący to zadanie nazywa się Googlebot. Istnieją jego dwa rodzaje: Googlebot na smartfony (org. Googlebot Smartphone), działający na urządzeniach mobilnych oraz Googlebot komputerowy (org. Googlebot Desktop), który imituje użytkownika komputera. Co ciekawe, aby uniknąć przeciążenia, robot ten nie może indeksować witryn zbyt szybko. Średni czas, w którym odbywa się „crawling” wynosi kilka sekund, ale jest to kwestia indywidualna dla każdej strony.
Roboty indeksujące (ang. spiders lub web crawlers) uzyskują dostęp do Twoich stron, czytają ich zawartość i podążają za linkami wewnętrznymi i zewnętrznymi podczas cykli indeksowania. Powtarzają ten proces, przechodząc z jednego linku do drugiego, aż przeszukają znaczną część Twojej witryny. Chociaż może to obejmować wszystkie adresy URL w małych witrynach, roboty będą kontynuować „pełzanie” tylko na dużych lub często aktualizowanych serwisach internetowych, dopóki ich budżet (ang. crawl budget – czas i zasoby przydzielone przez Google na analizowanie witryny) nie zostanie wyczerpany. Zgodnie z przekazem firmy, może to dotyczyć głównie serwisów z ponad 1 milionem unikalnych stron (ang. unique pages) aktualizowanych raz w tygodniu lub tych z ponad 10 000 unikalnych stron aktualizowanych każdego dnia. Innym rodzajem witryn, których może to dotyczyć, są te, w których wiele stron nie zostało jeszcze poddanych procesowi „pełzania” z powodu zagrożenia ich przeciążenia.
Indeksowanie („indexing”) następuje po opisanym wyżej „pełzaniu” i obejmuje analizę i przechowywanie informacji uzyskanych podczas pierwszego etapu procesu. Co ważne, zwykle odbywa się to zaraz po nim, chociaż nie jest to gwarantowane. Ten etap obejmuje analizę tagów treści i atrybutów, takich jak opisy alt, słowa kluczowe, struktura strony, filmy wideo, grafiki itp. Następuje tu również sprawdzenie, czy dana strona nie jest plagiatem. Po tym, jak Google zadecyduje, że strona jest kanoniczna, co oznacza oryginalną, jest ona wysyłana do obszernej biblioteki – Google index – zawierającej miliardy stron internetowych. Warto wiedzieć, że nie każda strona jest indeksowana, ponieważ wyszukiwarki priorytetowo traktują te, które uważają za istotne.
Jak sprawić, by Google ponownie przeszukało Twoją witrynę?
Jeśli dodajesz nowe treści, bądź wprowadzasz znaczące zmiany, zaleca się, aby Google ponownie zweryfikowało Twoją witrynę. Istnieją dwa podstawowe sposoby, aby tego dokonać, w zależności od liczby adresów URL, które chcesz poddać procesowi:
-
- Jeśli niewielka liczba adresów URL musi zostać ponownie przeanalizowana, możesz skorzystać z narzędzia URL Inspection Tool. Będziesz jednak potrzebować dostępu do usługi Search Console. Oznacza to, że musisz posiadać uprawnienia użytkownika z pełnym dostępem lub właściciela. Oto jak możesz przesłać swoje żądanie:
- po zalogowaniu się do Google Search Console wklej swój adres URL w pasku wyszukiwania na górze i kliknij „Enter”. Następnie wybierz „POPROŚ O ZINDEKSOWANIE” (funkcja ta zadziała również, jeśli strona nie była jeszcze wcześniej zindeksowana),
- jeśli strona przejdzie kontrolę pod kątem możliwych błędów indeksowania (po prostu nie dostaniesz informacji o błędzie), oznacza to, że czeka ona w kolejce. Unikaj zgłaszania tych samych adresów URL w kółko, ponieważ nie przyspieszy to procesu;
- Jeśli niewielka liczba adresów URL musi zostać ponownie przeanalizowana, możesz skorzystać z narzędzia URL Inspection Tool. Będziesz jednak potrzebować dostępu do usługi Search Console. Oznacza to, że musisz posiadać uprawnienia użytkownika z pełnym dostępem lub właściciela. Oto jak możesz przesłać swoje żądanie:
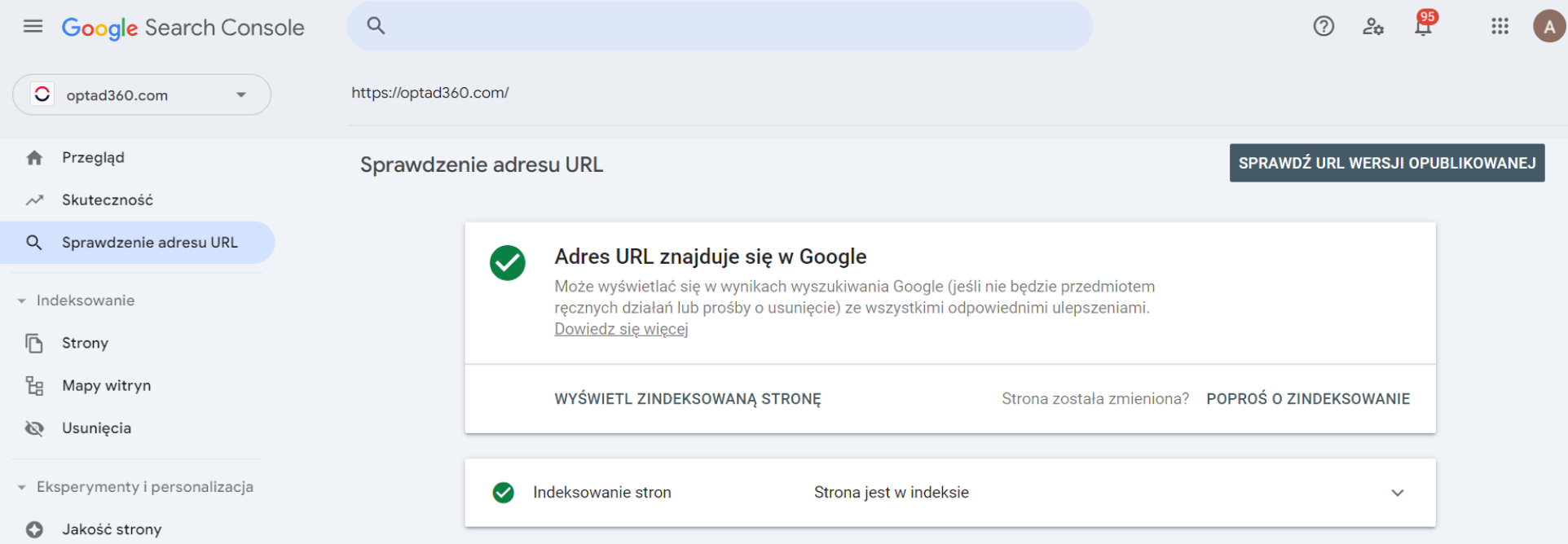
- Jeśli chcesz przeanalizować więcej adresów URL naraz, możesz przesłać mapę witryny (ang. sitemap). Jest to plik zawierający szczegóły dotyczące zawartości Twojej witryny i połączeń między jej elementami. Pamiętaj, że nawet po jej przesłaniu nie ma gwarancji, że wszystkie Twoje strony zostaną ponownie przeanalizowane. Mapę swojej witryny możesz utworzyć lub, w niektórych przypadkach, nawet zdobyć wersję gotową do użycia. Aby przesłać swoją mapę witryny, musisz wskazać ścieżkę dostępu do niej, zmieniając i dodając taki wiersz do pliku robots.txt: https://przykład-strony.com/my_sitemap.xml.
„Crawling” i „indexing” – wskazówki optymalizacyjne
-
- Upewnij się, że Twoje strony zostały zauważone przez roboty Google (możesz to zrobić w Google Search Console, tak jak w krokach opisanych powyżej, i poprosić o zindeksowanie, jeśli zauważysz, że Twoja witryna nie została zaindeksowana);
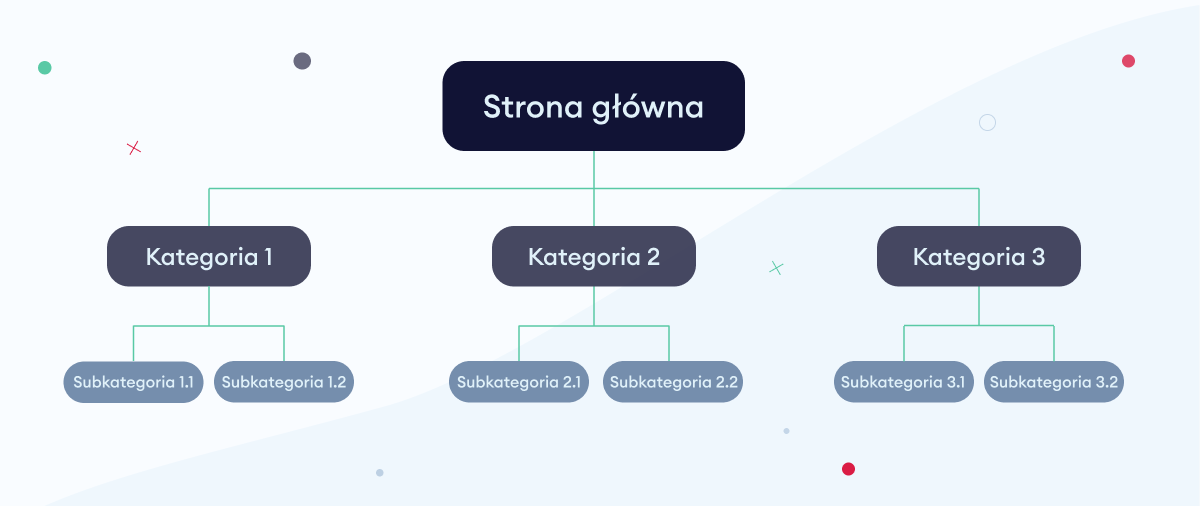
- Zoptymalizuj strukturę witryny, jeśli nie jest ona logiczna. Najlepiej, jeśli jest to tradycyjna struktura piramidy, która wygląda jak na poniższej grafice:
- Spróbuj przyspieszyć działanie swojej strony – nie może ładować się zbyt długo, ponieważ roboty nie będą analizować jej tyle, ile by mogły, ze względu na ograniczenia czasu dotyczące każdej witryny. Ponadto powinieneś przeczytać nasz artykuł o podstawowych wskaźnikach internetowych, w którym wskazujemy inne powody, dla których szybkość ładowania ma kluczowe znaczenie;
- Umieść w swojej witrynie linki wewnętrzne, które umożliwią robotom przechodzenie między stronami;
- Jeśli Twoja strona nie jest responsywna – spróbuj naprawić to jak najszybciej. Od 2016 roku Google zdecydowało się skupić na indeksowaniu mobilnym (org. mobile-first indexing), co oznacza, że poświęca szczególną uwagę mobilnym wersjom witryn;
- Nie pozwól, aby uszkodzone linki wprowadzały w błąd Googlebota. Znajdź błędy 404 w Twojej witrynie i usuń lub zaktualizuj te strony;
- Korzystaj z pliku robots.txt, jeśli chcesz zablokować niektóre sekcje swojej witryny, jednak upewnij się, że dostęp do ważnych dla Ciebie stron nie jest uniemożliwiony;
- Twórz wyłącznie treści wysokiej jakości. Google ceni wyjątkowość i użyteczność, a potrzeby użytkownika stawia na pierwszym miejscu.
Optymalizuj i monetyzuj
„Crawling” i „indexing” to dwa odrębne, ale kluczowe procesy dla skutecznego SEO. Podczas gdy pierwszy z nich zapewnia, że wyszukiwarki odkrywają zawartość Twojej witryny, drugi obejmuje analizę jej zawartości w celu zrozumienia jej przydatności i znaczenia. Aby zapewnić swojej witrynie jak najlepsze SEO, aby zajmowała wyższe miejsca w rankingu wyszukiwarek, koniecznie zoptymalizuj swoje strony. Gdy już to zrobisz, spraw, aby Twoje treści generowały dla Ciebie zarobki! Aby uzyskać pomoc w tym zadaniu, zapoznaj się z wymaganiami dołączenia do sieci optAd360, wypełnij formularz rejestracyjny i dołącz do nas!
Przeczytaj również

Agentic AI – jak mali wydawcy mogą się zrównać z dużymi firmami w produkcji treści w 2026 roku?
Chcesz dowiedzieć się, czym są Agenci AI i jak mogą pomóc Ci w pracy twórcy treści internetowych? Zachęcamy do zapoznania się z tym artykułem już teraz!
Czytaj więcej
Wiarygodna strona internetowa – jak zrobić to dobrze
Czy znasz pojęcie website credibility? To niewielka zmiana, która wpłynie pozytywnie na każdy aspekt Twojej witryny. Zaciekawiony? Jeśli tak, nie szukaj dalej! W tym artykule dowiesz się wszystkiego, co musisz wiedzieć o wiarygodności strony www.
Czytaj więcej